Concepts and heritage
PgQue is a snapshot-based shared event log with per-consumer position tracking. It is not SKIP LOCKED, and it is not row-claiming. Events are not handed out one at a time; they become visible in batches, between ticks. Understanding those two ideas — the snapshot batch and the rotating log — explains everything else: why there are no row locks, why fan-out is free, and why the queue produces no dead tuples on its hot path.
Mental model
Picture one append-only log per queue. Producers append events. Consumers do not remove events; each consumer keeps a cursor that records how far it has read. A periodic heartbeat — the tick — slices the log into batches, and a consumer always receives the next whole slice it has not yet seen.
Because the log is shared and each consumer carries its own cursor, fan-out is native. Ten consumers on one queue each see every event exactly once from their own point of view, with no per-consumer copy of the data — there is a single log, ten cursors.
Glossary
- Event — one row appended to a queue. Delivered at-least-once. Columns:
ev_id,ev_time,ev_txid(xid8),ev_retry,ev_type,ev_data,ev_extra1..4. PgQue does not interpret the payload — its format is a producer/consumer contract. - Queue — a named event stream backed by three rotating tables. Any number of queues coexist in one database.
- Producer — anything that calls
pgque.send/pgque.insert_event. Many producers may write the same queue concurrently. - Consumer — subscribes to a queue, reads batches, acknowledges them. Many consumers may subscribe to one queue; each has its own cursor and independently sees every event. That is fan-out, with no duplication of stored events.
- Consumer cursor — a consumer’s saved position in the log (its last finished tick). Reading does not consume from a shared pool; it advances this private marker.
- Tick — a position marker placed periodically in the stream. Ticks delimit batches. PgQue ticks 10 times per second by default (one tick every 100 ms).
- Batch — the set of events that fall between two consecutive ticks, served to a consumer together. A consumer processes a whole batch, then acknowledges it.
- Ticker — the background process that creates ticks (and drives rotation, retries, and maintenance). In the default
pg_cronpath, one 1-second cron slot callspgque.ticker_loop(), which invokespgque.ticker()everytick_period_ms. - Rotation — reclaiming old events by cycling through three inheritance child tables and
TRUNCATE-ing the oldest, instead of deleting rows.
The ticker rule
Keep the ticker running. No ticks means no batches means no delivery. Long pauses produce one huge batch a consumer cannot digest.
This is the single most important operational fact. If receive() returns nothing forever, the ticker is almost always the cause — see installation.md for setting it up and monitoring.md for confirming it runs.
The snapshot rule
Each tick stores a Postgres snapshot — the tick_snapshot (pg_snapshot) column — capturing exactly which transactions were visible at that instant. A batch is then defined as a diff between two snapshots: the events visible in the current tick’s snapshot but not in the previous tick’s snapshot.
That two-snapshot diff is the whole trick. To assemble a batch, PgQue does not scan for unlocked rows or mark rows as taken. It tests each event’s inserting transaction with pg_visible_in_snapshot(ev_txid, tick_snapshot) and keeps the rows that are visible in the new snapshot but were not yet visible in the old one. Because membership in a batch is decided purely by transaction visibility, there are no row locks and no per-row deletes anywhere in the delivery path. Every consumer can run the same visibility test against its own cursor’s snapshots and get its own batches from the same shared rows.
The diff is built precisely so that it captures every transaction that committed between the two ticks — including stragglers. A producer transaction can still be in progress when the earlier tick is taken and only commit before the later one; its events belong in the batch even though the producer’s ev_txid is below the earlier snapshot’s high-water mark. PgQue handles this by comparing the two snapshots’ in-progress transaction lists (pg_snapshot_xip): a transaction listed as in progress at the earlier tick but no longer in progress at the later one committed in the window, so its events are pulled in by transaction id alongside the visibility test. Nothing is missed and nothing is delivered twice within a batch.
This is also what keeps the diff cheap under load. Rather than scanning every event back to the snapshot’s xmin — which a single long-running transaction would drag arbitrarily far into the past — the batch query bounds its ev_txid scan to the range between the two snapshots’ xmax values, the band of transaction ids that could actually have completed between the ticks. The work to build a batch therefore tracks the events in that window, not the age of the oldest open transaction on the system. Christophe Pettus’s external walk-through, Two Snapshots and a Diff, traces the same mechanism step by step.
One consequence follows directly: a producer’s insert and the tick that should pick it up must commit in separate transactions. An event inserted in the same transaction as the tick is still in progress at snapshot time, so it is not yet visible and is excluded from that batch. Conversely, receive → process → ack belongs in one transaction when you want exactly-once side effects on the same database. The shipped Go and TypeScript clients satisfy the producer-side rule transparently because each call runs in its own implicit transaction; the Python client needs an explicit commit between send and the consumer side. See examples.md for the transactional pattern.
Cooperative consumers vs fan-out
Experimental in PgQue 0.2. The cooperative-consumer API ships in the default install but is marked experimental; treat it as subject to change.
PgQue offers two different consumer shapes on top of the same shared log. They are easy to confuse because both involve “several workers on one queue”, but they distribute events in opposite ways.
Native fan-out is the default. Every registered consumer keeps its own cursor (sub_last_tick) and independently sees every event. Three consumers — say audit, email, analytics — each receive a full copy of the stream from their own point of view, advancing at their own pace. The event is stored once; there is no per-consumer copy. This is the right model when distinct subsystems each need all the events.
Cooperative consumers invert that within a single consumer. One logical consumer (the cooperative main, sub_role = 'coop_main') owns a single cursor, and a pool of subconsumers (sub_role = 'coop_member') draw different batches from it. Each event is delivered to exactly one subconsumer in the pool — competing consumers sharing one fan-out cursor. This is the right model when you want to spread one subscriber’s workload across a horizontally scaled pool of identical workers.
The two compose: a queue can have several independent fan-out consumers, and any one of them can be a cooperative group with its own pool of subconsumers underneath.
- Use fan-out when every consumer needs every event (different subsystems, different side effects).
- Use cooperative consumers when one subscriber’s events should be split across interchangeable workers for throughput, and a given event must be handled once within that pool.
See examples for the cooperative recipe and reference for signatures.
When cooperative consumers matter
The use case that comes up again and again: the queue itself is fast, but the downstream side effect is not. When one message means one slow external call — a transactional email API call (Resend, SendGrid), an SMS request, a webhook, or a slow HTTP POST — consumer-side parallelism is what decides whether the backlog drains or lingers. PgQue does not need a second queue to spread that load: one main consumer fetches a batch and fans the work out to a pool of subconsumers, each pulling its own slice cooperatively.
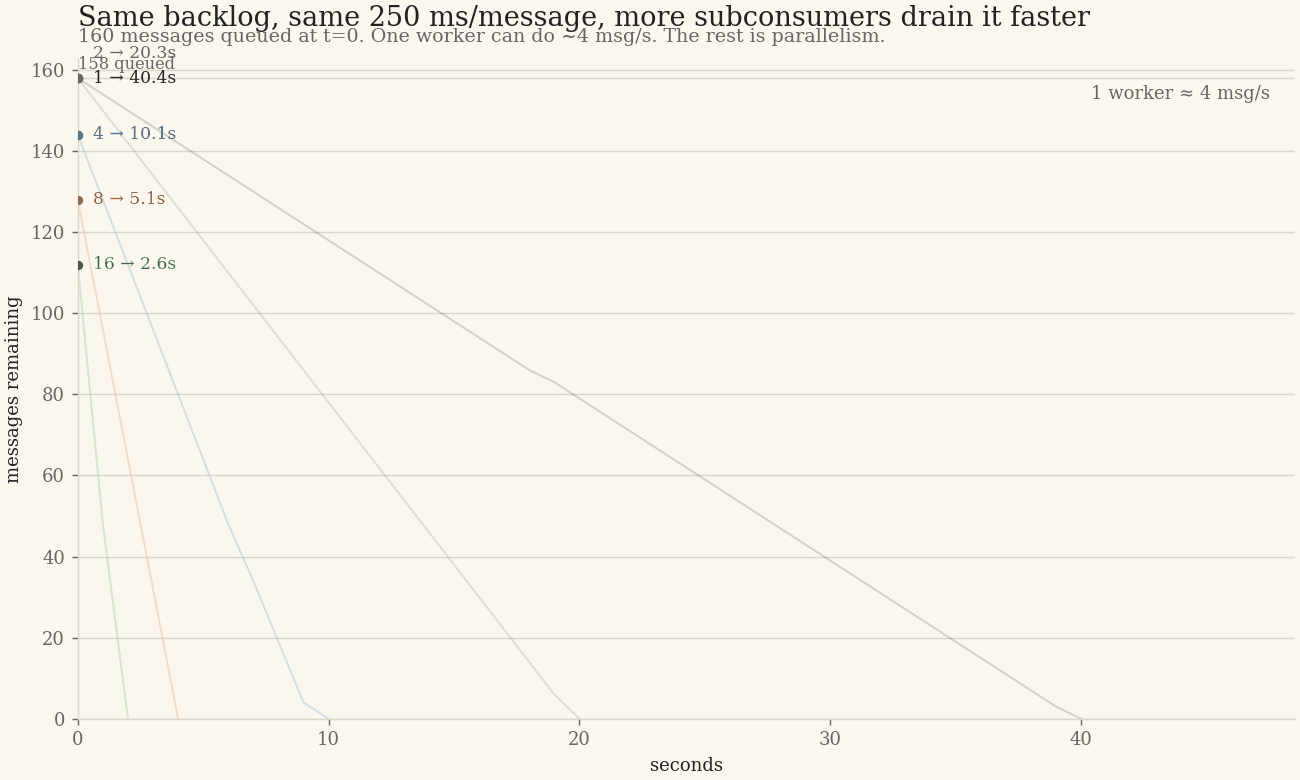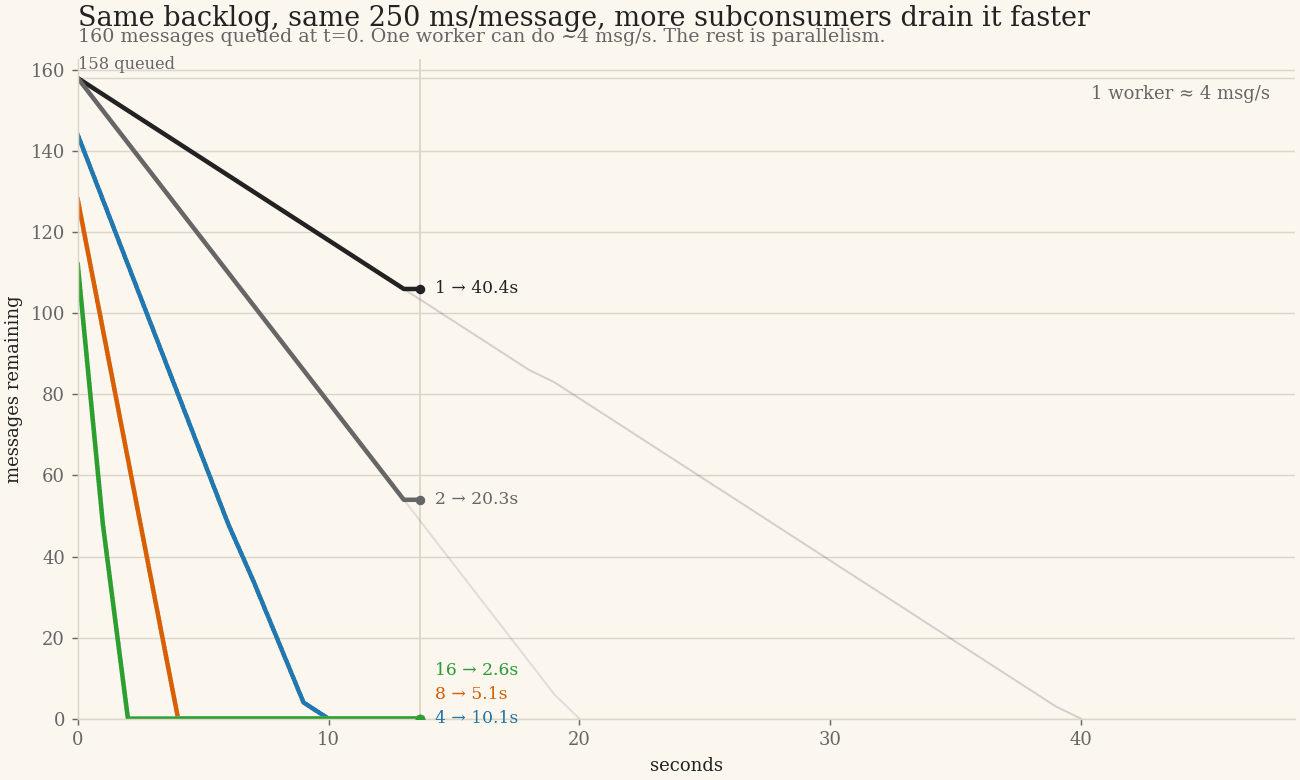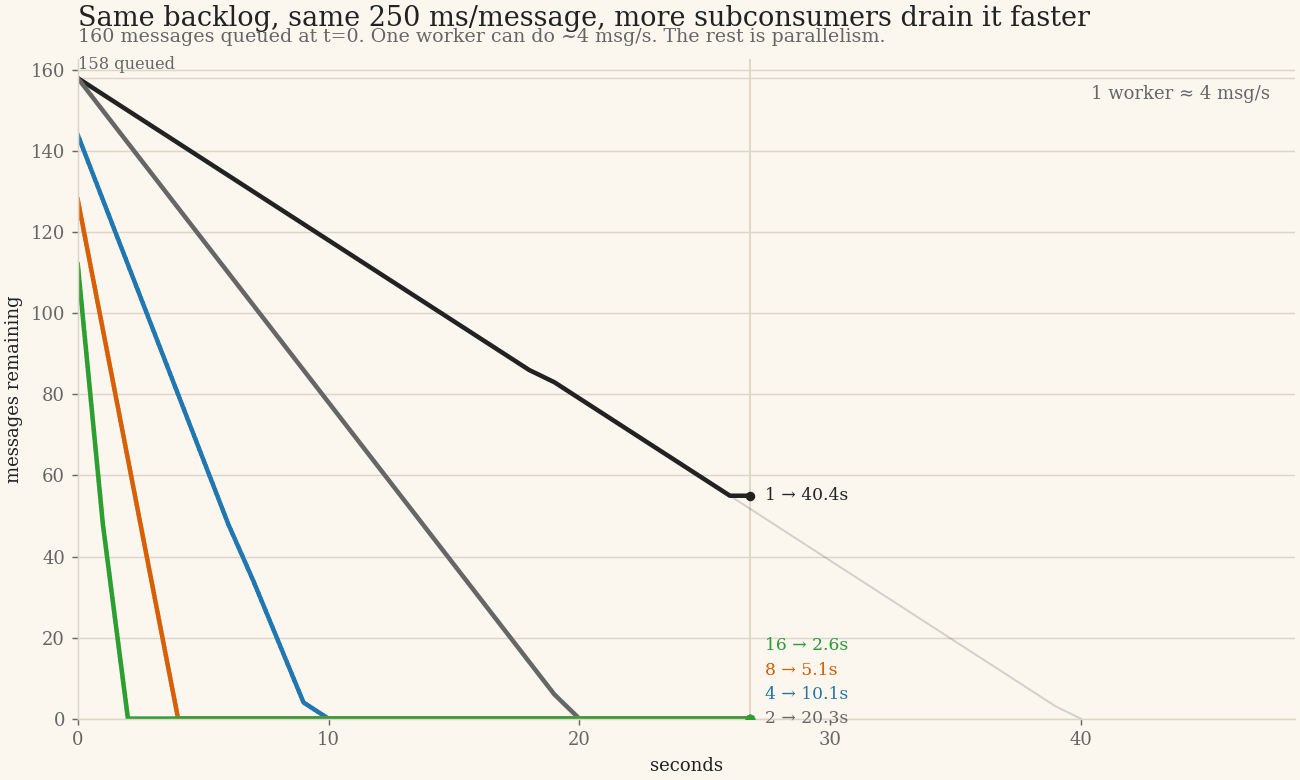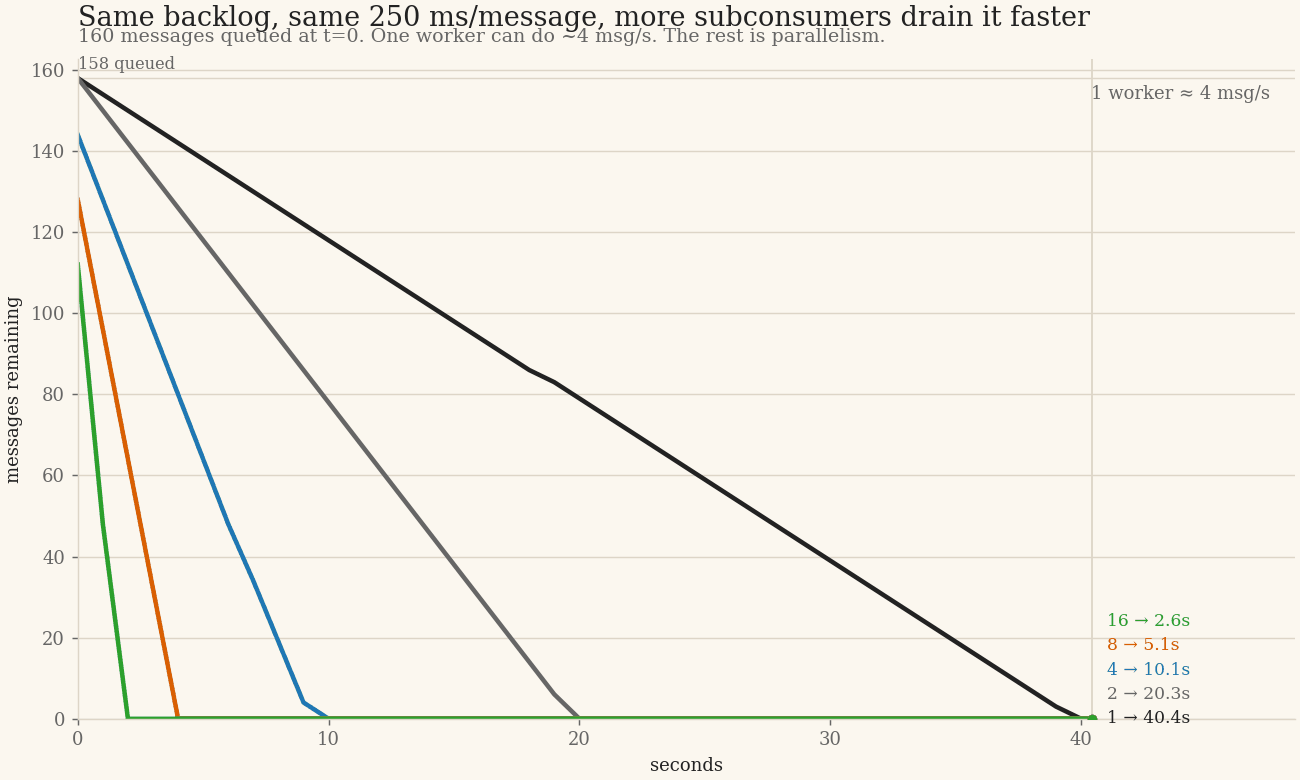
The takeaway is qualitative: when downstream work dominates, a single consumer is throughput-bound by that work, and adding cooperative subconsumers scales throughput and backlog drain close to linearly until some other bottleneck appears. The effect is reproducible on your own hardware.
Why zero bloat
A SKIP LOCKED queue stores work as rows that are inserted, locked, processed, and deleted. Every processed job leaves a dead tuple behind, and the table relies on VACUUM to reclaim that space. That is fine until something holds the xmin horizon — a long-running transaction, a stalled replica, a forgotten REPEATABLE READ session — at which point VACUUM cannot reclaim anything newer than the held xmin, dead tuples pile up, and the hot table bloats.
benchmark/xmin-horizon/ run: the SKIP LOCKED queue accumulates dead tuples it cannot vacuum, while PgQue stays flat at zero.PgQue’s hot path never deletes a row. Events accumulate in the active child table; old events are reclaimed by rotation, not by VACUUM. Each queue is three child tables under a parent (using table inheritance, INHERITS, not declarative partitioning). When the rotation period elapses, the ticker advances to the next child and TRUNCATEs the one it is reusing. TRUNCATE drops the whole table’s storage at once and leaves no dead tuples to vacuum. Inheritance is used rather than native partitioning precisely because a cheap, per-table TRUNCATE-and-reuse cycle is exactly what rotation needs.
The trade-off — and the one thing to monitor — is that rotation can only TRUNCATE a child once every consumer has read past it. Rotation looks at the lowest tick still pinned by any subscription; if the slowest consumer has not advanced past the table about to be reused, rotation skips it. So a stopped or chronically slow consumer pins the lowest tick, blocks rotation, and lets the event tables grow. The fix is not vacuum tuning — it is keeping consumers healthy. Watch consumer lag in monitoring.md.
Evidence: held xmin horizon
The committed benchmark in benchmark/xmin-horizon/ makes the difference concrete. It runs a SKIP LOCKED queue and PgQue side by side under identical load — 4 producers, 4 consumers, 2 bystander clients on an unrelated 1M-row table, producers rate-limited to 800 transactions per second, aggressive autovacuum on both — on Postgres 17. Scenario s1 is the baseline; scenario s2 holds a single REPEATABLE READ transaction open for the entire run, pinning the xmin horizon.
| Scenario | Workload | Dequeue (jobs/s) | n_dead_tup | Bystander avg latency (ms) |
|---|---|---|---|---|
| s1 (baseline) | SKIP LOCKED | 797 | 6,397 | 1.35 |
| s1 (baseline) | PgQue | 792 | 0 | 1.50 |
| s2 (held xmin) | SKIP LOCKED | 517 | 91,593 | 2.05 |
| s2 (held xmin) | PgQue | 804 | 0 | 1.45 |
Under the held xmin horizon, the SKIP LOCKED queue’s dead tuples climb from 6,397 to 91,593 — roughly 14× — its table grows about 15×, and dequeue throughput drops from 797 to 517 jobs/s, about a 35% loss. Bystander latency on the unrelated table rises too, because the bloated hot table competes for buffer cache.
PgQue, with the same xmin holder in place, keeps n_dead_tup = 0 across all pgque.event_* tables and zero autovacuum runs — throughput is unchanged (792 jobs/s baseline, 804 under the held xmin). Rotation defers reclamation to TRUNCATE rather than depending on VACUUM, so a blocked xmin horizon simply does not touch the queue’s hot path.
The figures above come from benchmark/xmin-horizon/results/results.md (summary table) and the per-cell final-bloat.csv and metrics.csv under results/s1-skiplocked, results/s1-pgque, results/s2-skiplocked, and results/s2-pgque. The reproducer — compose.yaml, Makefile, scripts/, and sql/ — is committed alongside them.
Evidence in the wild
The same SKIP LOCKED failure mode shows up repeatedly in production write-ups:
- Brandur / Heroku (2015) — a 60k-job backlog accumulating within an hour as dead tuples outran
VACUUM. - PlanetScale (2026) — a queue “death spiral” under sustained load with an analytical workload on the side.
- River issue #59 — autovacuum starvation on the queue table.
These are independent reports about other systems, cited here as evidence that the bloat tax is real, not a synthetic concern. PgQue avoids the whole class by construction — its hot path never deletes a row.
How PgQue compares
| Feature | PgQue | PgQ | PGMQ | River | Que | pg-boss |
|---|---|---|---|---|---|---|
| Snapshot-based batching (no row locks) | yes | yes | no | no | no | no |
| Zero bloat under sustained load | yes | yes | no | no | no | no |
| No external daemon or worker binary | yes | no | yes | no | no | no |
| Pure SQL install, managed Postgres ready | yes | no | yes | yes | yes | yes |
| Language-agnostic SQL API | yes | yes | yes | no | no | no |
| Multiple independent consumers (fan-out) | yes | yes | no | no | no | yes |
| Built-in retry with backoff | yes | yes | partial | yes | yes | yes |
| Built-in dead letter queue | yes | no | partial | partial | no | yes |
Per-system notes:
- PgQ is the Skype-era engine PgQue derives from — same snapshot/rotation architecture, but it requires a C extension and the external
pgqddaemon, neither available on managed Postgres. PgQue removes both. - PGMQ retry is visibility-timeout re-delivery (
read_cttracking), without configurable backoff or a max-attempts cap. - River is a Go background-job framework on Postgres: it claims jobs with
SKIP LOCKEDandDELETEs completed jobs, so its job table accumulates dead tuples under sustained load, and it needs a long-running Go worker process. Competing-consumers over a job table, not a shared log with independent cursors. - Que uses advisory locks rather than
SKIP LOCKED— so claiming creates no dead tuples — but completed jobs are stillDELETEd, which does. Ruby-only. - pg-boss fan-out is copy-per-queue (
publish()/subscribe()inserts one row per subscriber per event), not a shared log with independent cursors. - Category: River, Que, and pg-boss are job-queue frameworks (per-job lifecycle, a worker binary in Go/Ruby/Node.js). PgQue is an event/message queue — a shared log with fan-out, closer to a Kafka topic.
What sets PgQue apart, verified against the engine:
- Zero event-table bloat, by design. No per-row claim or delete on the hot path — events accumulate in the active child table and space is reclaimed by
TRUNCATE-based rotation, so no dead tuples and no dependence onVACUUM. Immune to xmin-horizon pinning (see the held-xmin benchmark above). - Native fan-out. Each registered consumer keeps its own cursor (
sub_last_tick) over one shared event log and independently sees every event. The event is stored once; there is no copy-per-subscriber.
When to use PgQue vs a job queue
- Choose PgQue when you want event-driven fan-out, no bloat to tune around, and a language-agnostic SQL API, and you do not need per-job priorities or a worker framework.
- Choose a job queue when you need per-job lifecycle, sub-millisecond dispatch, priority queues, cron scheduling, unique jobs, or deep ecosystem integration (Elixir / Go / Node.js / Ruby).
Heritage
PgQue inherits a queue engine that has been in production for over a decade.
- 2006 — PgQ started at Skype, by Marko Kreen, inspired by Slony.
- 2007 — Open-sourced as part of SkyTools. Its first user was Londiste replication.
- 2009 — SkyTools 3 added cascading and cooperative consumers. Presented at PgCon by Marko Kreen and Martin Pihlak (slides).
- 2026 — PgQue: a single-file, PG14+ repackage for managed databases.
PgQ ran on large self-managed Postgres at Skype, where hundreds of queues drove replication and event distribution. In its original form it depended on a C extension plus the pgqd daemon — neither of which is available on managed Postgres, where you cannot load C extensions or run a custom daemon next to the database. A PL/pgSQL-only path was later added to PgQ so the engine could run as plain SQL. That pure-SQL path is what PgQue is built on.
PgQue preserves the PgQ batch, tick, rotation, and consumer-tracking engine unchanged — it is the sacred core — and modernizes the surface for Postgres 14 and later:
xid8andpg_snapshot(viapg_current_xact_id(),pg_current_snapshot(),pg_visible_in_snapshot()) in place of the legacy 32-bit transaction-ID types.pg_cron(orpg_timetable) to drive the ticker and maintenance, replacing the externalpgqddaemon.LISTEN/NOTIFYas a lossy wakeup hint after each tick, so consumers can react quickly without busy-polling — they still pollreceive(), the notify is only a nudge.- A modern convenience API —
send/receive/ack/nack, a dead-letter queue, andreader/writer/adminroles — layered cleanly on the inherited primitives.
Lineage: PgQ (Skype, ISC, © Marko Kreen / Skype Technologies OU) → SkyTools 2/3 → github.com/pgq/pgq → PgQue (Apache-2.0, © 2026 Nikolay Samokhvalov). See NOTICE for full attribution.
Further learning
Historical background:
- 2007 — SkyTools, the Postgres toolkit Skype open-sourced, where PgQ shipped as the queuing component alongside Londiste replication.
- 2009 — Marko Kreen (Skype), PGCon — PgQ, the original deck on the queue engine.
- 2026 — Alexander Kukushkin (Microsoft), Rediscovering PgQ, a deck revisiting the PgQ architecture.
PgQue coverage:
- 2026 — Christophe Pettus, PgQue: Two Snapshots and a Diff, an independent walk-through of PgQue’s snapshot-diff mechanism and why it avoids row locks and dead-tuple bloat.
- 2026 — Postgres.fm: PgQue (YouTube), with Nikolay Samokhvalov and Michael Christofides discussing PgQue’s architecture, use cases, and trade-offs.
- 2026 — Scaling Postgres 416: Zero Bloat Postgres Queue (YouTube), with PgQue as the episode’s lead story.
- 2026 — Postgres Weekly #645: A Kafka-like pure SQL queue for Postgres, where PgQue was the issue’s headline.
- 2026 — Hacker News discussion.
Where to go next
- tutorial.md — a hands-on first queue.
- reference.md — every function in the default install.
- examples.md — fan-out, exactly-once, and other patterns.
- monitoring.md — watching consumer lag and ticker health.
- latency-and-tuning.md — tick cadence and delivery latency trade-offs.